Backend Architecture
Our application will utilize the basic components of a web application. Chef-It! will operate based on Amazon Web Services (AWS). The software architecture of Chef-It! will consist of two main parts: Client and Backend.
Client
Overview
The Client is any device running the application. These devices will include, at minimum, supported browsers running on a computer (laptop or desktop) or the Chef-It! App on smartphones or tablets. The team at Chef-It! will develop their own iOS and Android apps. In doing so, the team at Chef-It! will be able to control the app and other devices through the SDK for the following reasons:
- Will allow us to utilize efficiencies on each operation system to provide a better experience for every user on every client and device
- Provide the capability to adapt services smoothly and transparently under various circumstances
Components
Chef-It! has requirements to be responsive, fast, and highly available. Chef-It! will control its performance via the software development kit (SDK). Figure C-1 illustrates a typical client structure.
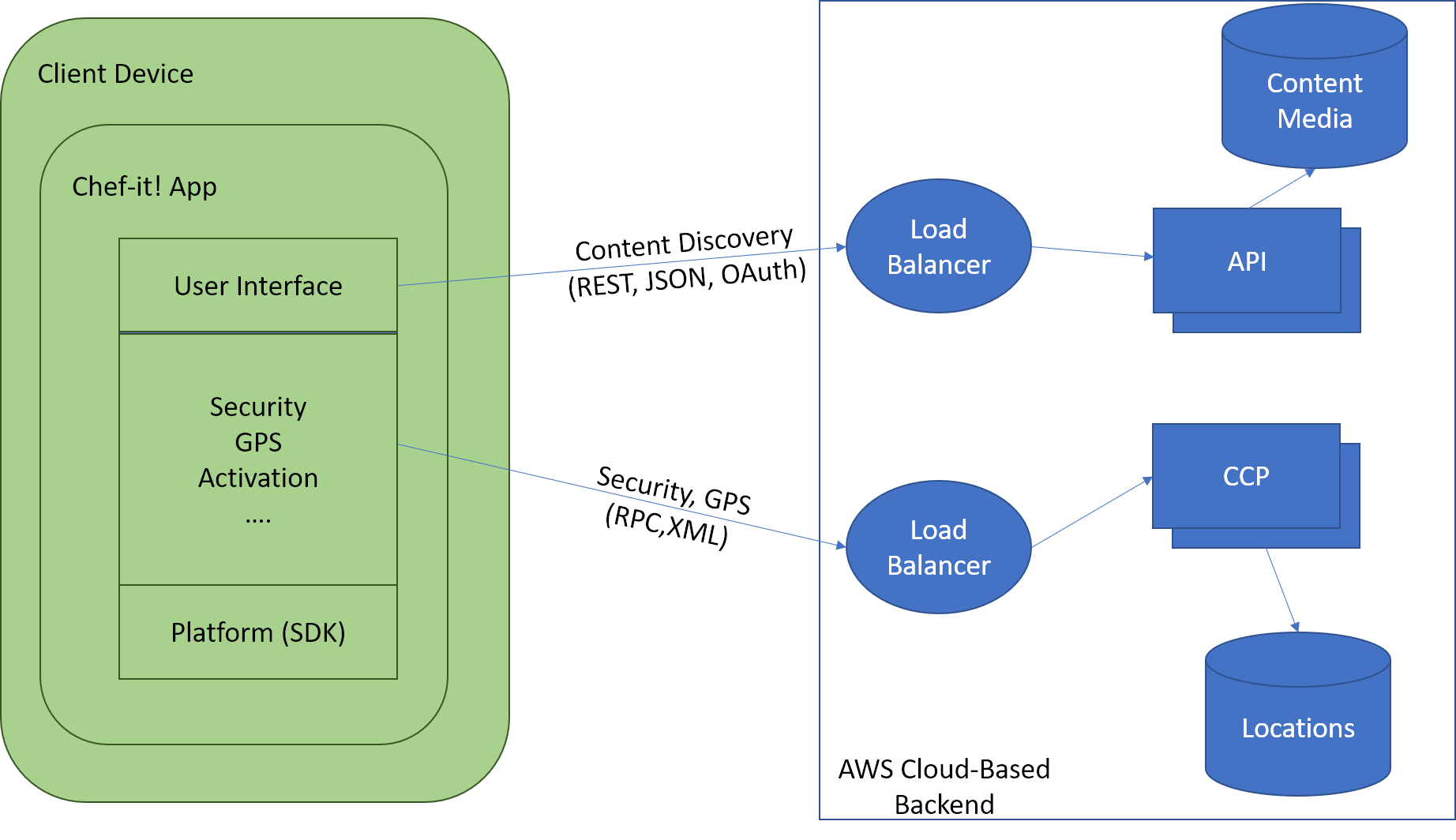
Figure C-1. Example of system path/logic per client connection type.
Client Apps will separate connections to the backend into 2 categories: content discovery and grocery tracking. The content discovery will provide data to display on the UI including recipes, user information, ingredients, and videos. The grocery tracking will utilize built-in GPS on most smartphones and geo-location services on other clients to provide constant polling to the Chef-It! Control Plane (CCP) to constantly update a user’s location to find grocery stores nearby, access their APIs, and find deals/pickup services.
Backend
The backend of our system comprises almost everything including services, databases, and storages and will run entirely on AWS cloud. Some components of the Backend include:
- Databases: Chef-It! will primarily use scalable distributed databases such as Cassandra and/or AWS DynamoDB.
- Business logic Microservices: Various frameworks created by Chef-It! developers.
- Computing Instances: utilize AWS EC2 which can be easily scaled to meet future demand.
Architecture
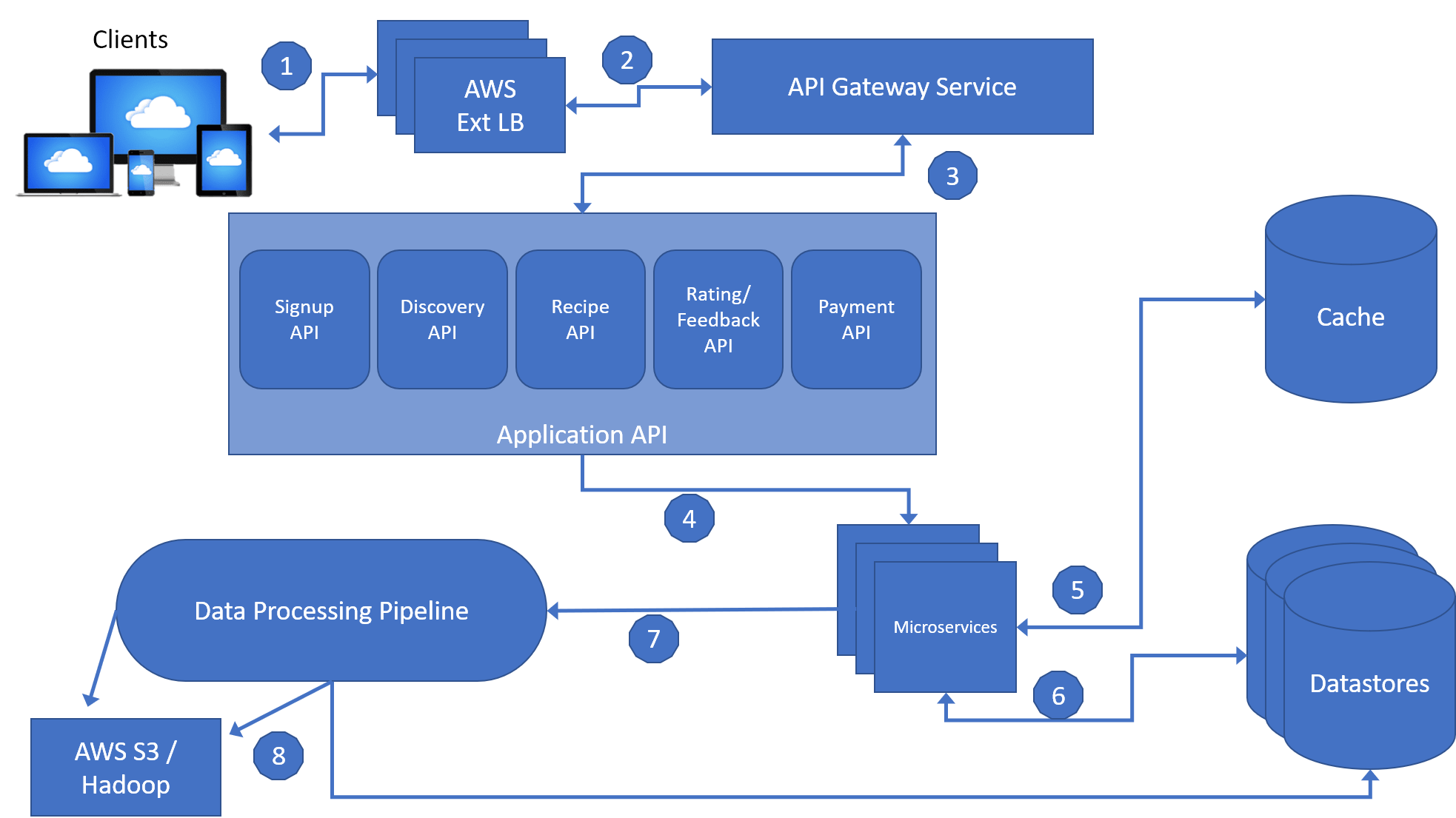
Figure BA-1. The Chef-It! Backend Architecture.
- The client sends a request to the Backend. Since the Backend is running on AWS the request is handled by an AWS Load Balancer (AWS Ext.LB).
- The AWS Ext. LB will forward the request to the API Gateway Service running on EC2 instances. The API Gateway Service is named “Edge” and is built by the Chef-It Team to allow dynamic routing, traffic monitoring and security, and increase resilience to failures. The Edge component will take the request and apply it to predefined filters corresponding to business logics and then forward the request to the Application API for further handling.
- The Application API component contains the core business logic behind the chef-it application. All of the APIs are contained within this module and include several different types of APIs, each corresponding to different user activities/capabilities. Some examples include the Signup API, where users can register, or a Recommendation API for retrieving recipe recommendations.
- The API will call a microservice (or sequences of microservices) to fulfill the request. An example would be the Signup API. Which would call a microservice to obtain, validate, and compare data in the request with data from the datastores. Then it would utilize another microservice to send a verification email or text message to the user at the appropriate email or phone number.
- Microservices are the backbone of the backend architecture, and are small stateless programs that fulfill incoming requests through an API. Due to the complexity of the system, Chef-It! will utilize the open source software called Hystrix (by Netflix) to isolate each microservice from the caller process. This will allow us to control cascading failures and enable resilience. After each run, Hystrix will cache its result to allow faster access for specific critical requests.
- Microservices can utilize the datastores and cache to save or obtain data during its process.
- Microservice can utilize the Processing Pipeline for real time processing or batch processing.
API Gateway Service
Chef-It! will design the API Gateway service while utilizing Netflix’s open source Zuul [5] implementation. Zuul’s software was chosen primarily for its resiliency and scalability capabilities. If there is a need to increase service availability, this component can easily be deployed to EC2 instances across different regions.The API Gateway service resolves all requests from clients by communicating with the AWS External Load Balancers.
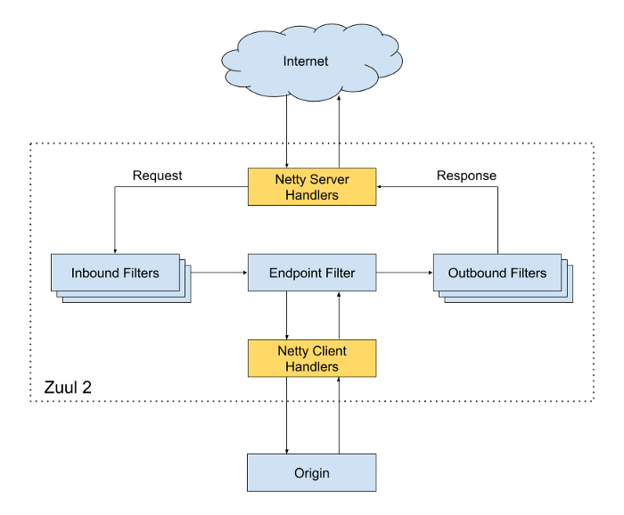
Figure BA-2. Overview of Zuul: The API Gateway Service.
Initially, the request gets routed to the Netty Server Handlers which are responsible for handling the network protocol, web server, and proxying work. This abstraction leaves the majority of heavy lift to the filters. The request is sent to the inbound filters which can be used for authentication, routing and manipulating the request. Next, the request is sent to an endpoint filter which can return a static response or route the request to the appropriate Application API in the backend. Lastly, before a response is sent, it gets decorated by the Outbound filters which also track metrics such as error rates, return codes, etc. These metrics will be monitored by the Chef-It! Team for continuous improvement and anomaly detection. Zuul is also able to discover new Application API by integrating with our service discovery module. This will allow for onboarding new application APIs, load tests, and service rerouting seamlessly, without impact to uptime or customers.
Application API
The application API is directly tied to Chef-It!’s core business functionalities. It serves as the orchestration layer to the other microservices. The API will follow the RESTful API [6] format to increase compatibility and reusability, as it is the architectural standard for web-based applications. The API proves the logic of converting a request to a composition of calls to the underlying microservices in correct order. While conducting these calls, the Application API can obtain additional data from other data stores to construct the appropriate responses. Chef-It!’s Application API is comprised of 8 categories:
- Signup API-provides functionality for non-members such as sign-up, trials, billing, etc.
- Login API- provides functionality for members such as user authorization such as login, account information
- Discovery API- used for searching recipes
- Grocery API- used for shopping for ingredients at local grocery stores
- Play API- for video streaming of recipe tutorials
- Feedback API- provides ability to users to provide feedback for recipes in the form of comments/posts and rating values.
- Payment API- provides functionality for all transactions.
- Ingredients API - provides the ability for users to select ingredients from recipes that they own and/or might need
The Application API component must be able to accept and process large columns of requests and construct appropriate responses. Our Architecture will utilize concepts from both synchronous and asynchronous execution calls.
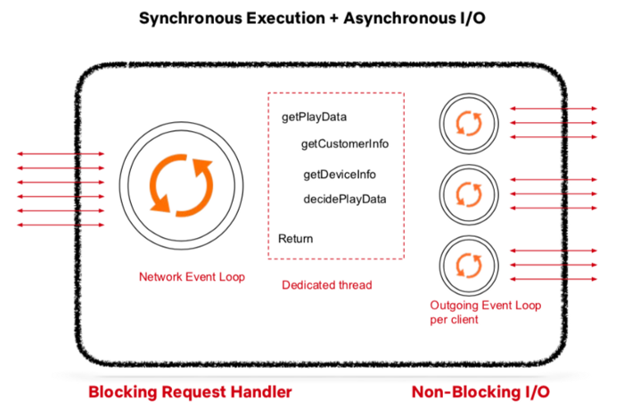
Figure BA-3. Execution methodology to handle large volumes of requests.
The input and outputs (I/O) will be asynchronous, with the inputs being the requests from the API gateway Service. Each request will then get placed into the Network event loop for processing. Rather than having independents threads (async execution), we will utilize a synchronous exception call stack and thread handler to block each request to run certain commands such as getDeviceInfo, get Customer Info, etc. before going to a non blocking output known as the Outgoing Event Loop. This loop will call the appropriate microservices and once complete, the dedicated thread would construct the corresponding response.
Mircroservices
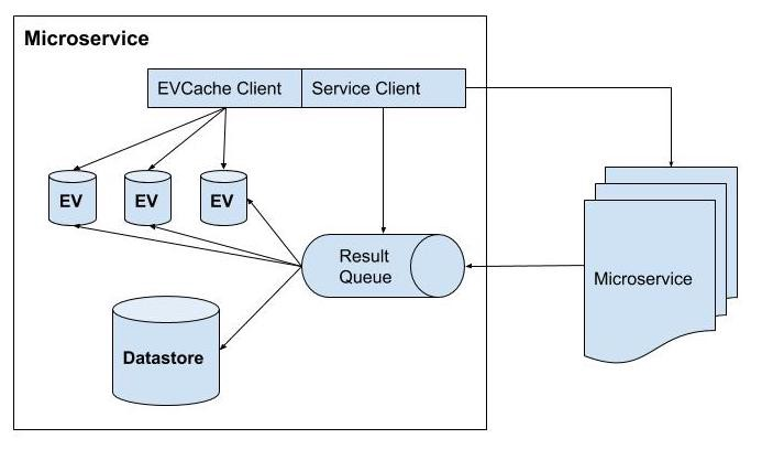
Figure BA-4. Overview of Microservice Implementation
A microservice can function as an independent module or can call other microservices via REST. Figure BA-4, illustrates the structural component of a microservice. The implementation of the microservices can utilize the Network event loop to obtain requests and results from other microservices. While each microservice can utilize its own datastore, it can store recent and/or heavily used queries or results into an in-memory cache.
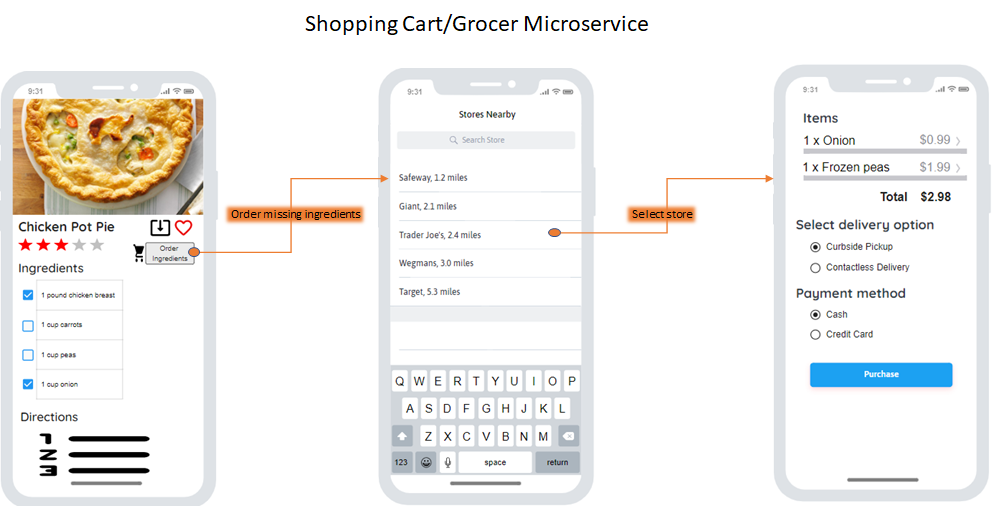
Figure BA-5. UI/UX of grocer microservice
Processing Pipeline
The processing pipeline is an essential piece of infrastructure that enables data driven engineering. The pipeline utilizes Kafka, a cluster messaging service, as its backbone. It is responsible for producing, collection, processing, aggregating and moving all microservice events in almost real-time. As Kafka utilizes a clustered event-driven architecture, combined with AWS cloud features, it is able to automatically scale as the number of users increases. Figure BA-6 below illustrates the general architecture of the processing pipeline.
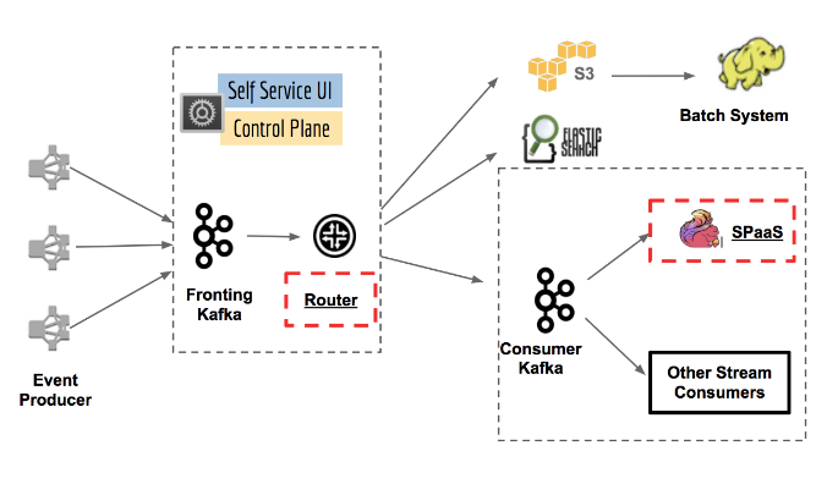
Figure BA-6. Event-Driven Architecture of Processing Pipeline
Events are produced by the microservices through API calls to the Kafka cluster. Based on the topic of the event, the router module (within Kafka) routes the message/request to different databases or applications such as elastic search or S3.The Kafka Consumer can take a message as an input and run different tasks including the decorating and routing of requests to the stream processing as a service platform. SPaaS will allow engineers to build and monitor their custom managed application while the platform can take care of scalability and operations.